Unraveling Insights in the Era of Data Overload
Written on
Chapter 1: The Data Landscape
As time progresses, we witness advancements in computing power, more affordable data storage solutions, and enhanced data transmission methods. These technological innovations have enabled the effortless collection, storage, and transfer of vast quantities of data at remarkably low costs. Consequently, a wide array of organizations, research institutions, governmental agencies, and even individuals are amassing extensive digital collections filled with documents, images, and audio files. Historically, the lack of data has posed a considerable obstacle to scientific and economic advancement. Yet, the assumption that merely accumulating data can resolve most challenges has proven to be misguided upon deeper reflection.
Reflecting on over two decades ago, when the initial draft of the human genome was unveiled, it represented information equivalent to around 1,000 books, each with 200 pages! Back then, many believed that cracking the “book of life” would give us the answers to all life-related questions, particularly insights into gene functions relevant to diseases. However, history illustrates that possessing this vast data (by reading the “book of life”) was merely the beginning, and it did not deliver the comprehensive understanding we sought. It’s clear that having data alone, regardless of its volume, is inadequate for problem-solving.
The genome is frequently likened to a book, but it employs a distinct genetic alphabet made up of only four “letters.” When these genetic “letters” are arranged in a specific sequence, they create what is known as a gene. If we view the genome as a book, then genes can be compared to sentences or paragraphs, each with various meanings and functions.

Chapter 1.1: Understanding Data
Data consists of individual instances, such as specific events, objects, individuals, or particular facts (for example, the statement: “My name is Alice, and I am 18 years old”). Data illustrate the characteristics or attributes of specific instances and can accumulate significantly, thanks to modern technology. While data is generally simple to gather or obtain, it provides insights into past or present occurrences. However, in its unrefined state, data does not inherently allow us to make predictions or forecasts about future events or larger trends. Often, we find ourselves with vast amounts of data yet fail to identify clear patterns; it’s akin to having pieces of a jigsaw puzzle without being able to see how they fit together—a common challenge in data analysis. For instance, a supermarket manager analyzing sales and customer records might discover that certain products are frequently purchased together. This revelation could lead to strategies such as positioning those items close on shelves or bundling them for promotions to enhance sales. Yet, uncovering such patterns (gaining knowledge) from the available data is not always straightforward. Despite our advanced technology and the abundance of data, the quest for knowledge remains unfulfilled.
“We are drowning in information but starved for knowledge.”
— John Naisbitt, Megatrends
Chapter 1.2: The Nature of Knowledge
In contrast, knowledge encompasses overarching principles, rules, patterns, structures, and laws applicable to categories or sets of instances (for example, the statement: “All living organisms require oxygen to survive.”). It transcends individual characteristics to identify patterns or consistencies that apply across various situations. Knowledge is often articulated in concise and clear statements, emphasizing simplicity and avoiding unnecessary complexity. The pursuit of knowledge can be intricate and time-consuming, involving research, experimentation, and education. Its primary strength lies in the ability to enable predictions and forecasts about the properties or behaviors of new cases within the framework of established principles.
The distinction between data and knowledge is crucial because it emphasizes that data serves as the foundation from which knowledge is derived, leading to more effective decision-making, problem-solving, and comprehension of complex phenomena.
Chapter 1.3: Data Analysis and the CRISP-DM Process
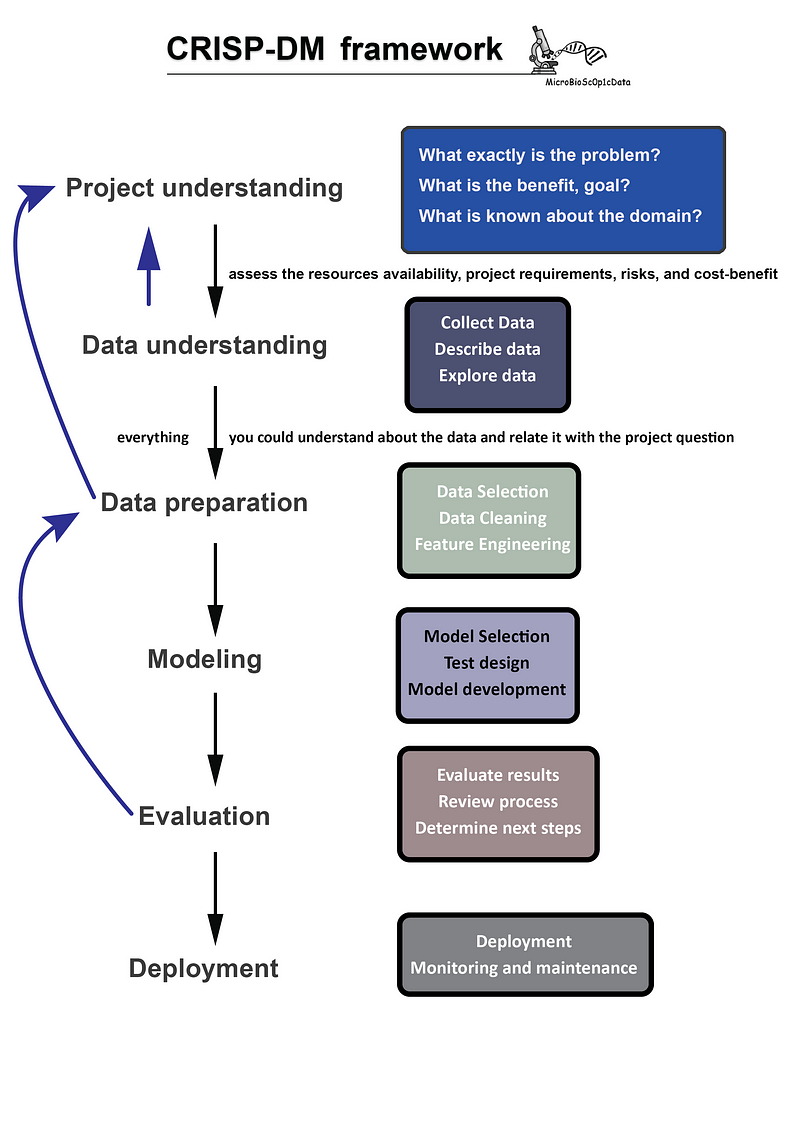
To extract knowledge from data, we must analyze it. The CRISP-DM (CRoss Industry Standard Process for Data Mining) framework is widely recognized for guiding data analysis. It comprises six phases:
- Project Understanding: Identify potential benefits, risks, and efforts involved in a successful project (business understanding).
- Data Understanding: Verify that sufficient data exists to tackle the problem or answer the inquiries (e.g., identifying missing values and outliers).
- Data Preparation: Select, correct, and modify data, and even generate new attributes to address the problem (a time-intensive process).
- Modeling: After preparing the data, choose and apply modeling tools to extract knowledge by creating a model.
- Evaluation: Decide whether to continue with the project based on the results, adjust goals for better outcomes, or deploy the optimized model.
- Deployment: This may involve writing reports, creating software that utilizes the model for decision-making, etc.
The abundance of data in today’s world is undeniable; however, the presence of data does not equate to knowledge. Only through rigorous data analysis can we reveal the insights and patterns essential for acquiring knowledge. The narrative of the human genome, with its vast data equivalent, serves as a reminder that data represents just the starting point in our journey toward understanding. Established frameworks like CRISP-DM provide a structured approach for deriving meaningful insights. In this information-driven age, the pursuit of knowledge is an ongoing endeavor, and data analysis serves as our compass in navigating the complexities of our world.
Chapter 2: Engaging with Knowledge Discovery
This video, Unveiling Secrets: Knowledge Discovery in Databases, explores the intricacies of transforming data into actionable insights, highlighting methodologies and practices that can enhance our understanding of data.
The video, Understanding The Knowledge Graph Of HR: Galileo™ AI Unveiled, discusses the role of knowledge graphs in human resources, showcasing how AI can leverage data to improve decision-making and operational efficiency.
References:
[1] F. H. Berthold Christian Borgelt, Guide to Intelligent Data Analysis: How to Intelligently Make Sense of Real Data, 2010th edition. London; New York: Springer, 2010.